Gender Classification and Eyes Location Detection: A Two Task Problem
Note
See the notebook here
Run in Google Colab
In this example, we are going to implement a multi-task problem. We try to identify the gender of the people, as well as locating their eyes in the image. Hence, we have two different tasks: classification (to identify the gender) and regression (to find the location of the eyes). We are going to use a single network (a CNN) to perform both tasks, however, we will need to apply different loss functions, each proper to a specific task. For this example we will need to install a few libraries (such as OpenCV, wget). If you don’t have them, they can be installed as below:
%pip install poutyne # to install the Poutyne library
%pip install wget # to install the wget library in order to download data
%pip install opencv-python # to install the cv2 (opencv) library
Let’s import all the needed packages.
import math
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import wget
import zipfile
import cv2
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.models as models
import torchvision.transforms as tfms
from poutyne import set_seeds, Model, ModelCheckpoint, CSVLogger, Experiment, StepLR
from torch.utils.data import DataLoader, Subset, Dataset
from torchvision.utils import make_grid
Training Constants
num_epochs = 5
learning_rate = 0.01
batch_size = 16
image_size = 224
w, h = 218, 178 # the width and the hight of original images before resizing
set_seeds(48)
gender_index = 20 # in the CelebA dataset gender information is the 21th item in the attributes vector.
W = 0.4 # the weight of regression loss
imagenet_mean = [0.485, 0.456, 0.406] # mean of the ImageNet dataset for normalizing
imagenet_std = [0.229, 0.224, 0.225] # std of the ImageNet dataset for normalizing
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("The running processor is...", device)
CelebA Dataset
We are going to use the CelebA dataset for this experiment. The CelebA dataset is a large-scale face attributes dataset which can be employed as the training and test sets for the following computer vision tasks: face attribute recognition, face detection, landmark (or facial part) localization, and face editing & synthesis.
Fetching data
The section below consists of a few lines of codes that help us download the CelebA dataset from a public web source and unzip it. Downloading the CelebA dataset can be also done directly using torch.datasets.CelebA(data_root, download=True). However, due to the high traffic on the dataset’s Google Drive (the main source of the dataset), it usually fails to function. Hence we decided to download it from another public source but use it with torch.datasets.CelebA().
data_root = "datasets"
base_url = "https://graal.ift.ulaval.ca/public/celeba/"
file_list = [
"img_align_celeba.zip",
"list_attr_celeba.txt",
"identity_CelebA.txt",
"list_bbox_celeba.txt",
"list_landmarks_align_celeba.txt",
"list_eval_partition.txt",
]
# Path to folder with the dataset
dataset_folder = f"{data_root}/celeba"
os.makedirs(dataset_folder, exist_ok=True)
for file in file_list:
url = f"{base_url}/{file}"
if not os.path.exists(f"{dataset_folder}/{file}"):
wget.download(url, f"{dataset_folder}/{file}")
with zipfile.ZipFile(f"{dataset_folder}/img_align_celeba.zip", "r") as ziphandler:
ziphandler.extractall(dataset_folder)
Now, as the dataset is downloaded, we can define our datasets and dataloaders in its original way.
transforms = tfms.Compose(
[
tfms.Resize((image_size, image_size)),
tfms.ToTensor(),
tfms.Normalize(imagenet_mean, imagenet_std),
]
)
train_dataset = datasets.CelebA(data_root, split="train", target_type=["attr", "landmarks"], transform=transforms)
valid_dataset = datasets.CelebA(data_root, split="valid", target_type=["attr", "landmarks"], transform=transforms)
test_dataset = datasets.CelebA(data_root, split="test", target_type=["attr", "landmarks"], transform=transforms)
Here we can see how each dataset sample looks like:
print(train_dataset[0])

Regarding the complexity of the problem and the number of training/valid samples, we have a huge number of training/validation images. Since there are not a considerable variation between images (e.g., the eye coordinates in images do not vary considerably), using all images in the dataset is not necessary and will only increase the training time. Hence, we can seperate and use a portion of data as below:
train_subset = Subset(train_dataset, np.arange(1, 50000))
valid_subset = Subset(valid_dataset, np.arange(1, 2000))
test_subset = Subset(test_dataset, np.arange(1, 1000))
train_dataloader = DataLoader(train_subset, batch_size=batch_size, shuffle=True)
valid_dataloader = DataLoader(valid_subset, batch_size=batch_size, shuffle=False)
test_dataloader = DataLoader(test_subset, batch_size=batch_size, shuffle=False)
Here, we can see an example from the training dataset. It shows an image of a person, printing the gender and also showing the location of the eyes. It is worth mentioning that as we resize the image, the coordinates of the eyes should also be changed with same ratio.
sample_number = 3
image = train_dataset[sample_number][0]
image = image.permute(1, 2, 0).detach().numpy()
image_rgb = cv2.cvtColor(np.float32(image), cv2.COLOR_BGR2RGB)
image_rgb = image_rgb * imagenet_std + imagenet_mean
gender = "male" if int(train_dataset[sample_number][1][0][gender_index]) == 1 else "female"
print("Gender is:", gender)
w, h = 218, 178
# The coordinates vector of the datasets starts with X_L, y_L, X_R, y_R
(x_L, y_L) = train_dataset[sample_number][1][1][0:2]
(x_R, y_R) = train_dataset[sample_number][1][1][2:4]
w_scale = image_size / w
h_scale = image_size / h
x_L, x_R = (x_L * h_scale), (x_R * h_scale) # rescaling for the size of (224,224) and finaly to the range of [0,1]
y_L, y_R = (y_L * w_scale), (y_R * w_scale)
x_L, x_R = int(x_L), int(x_R)
y_L, y_R = int(y_L), int(y_R)
image_rgb = cv2.drawMarker(image_rgb, (x_L, y_L), (0, 255, 0))
image_rgb = cv2.drawMarker(image_rgb, (x_R, y_R), (0, 255, 0))
image_rgb = cv2.cvtColor(np.float32(image_rgb), cv2.COLOR_BGR2RGB)
image_rgb = np.clip(image_rgb, 0, 1)
plt.imshow(image_rgb)
plt.axis("off")
plt.show()

Network
Below, we define a new class, named ClassifierLocalizer, which accepts a pre-trained CNN and changes its last fully connected layer to be proper for the two task problem. The new fully connected layer contains 6 neurons, 2 for the classification task (male or female) and 4 for the localization task (x and y for the left and right eyes). Moreover, to put the location results on the same scale as the class scores, we apply the sigmoid function to the neurons assigned for the localization task.
class ClassifierLocalizer(nn.Module):
def __init__(self, model_name, num_classes=2):
super(ClassifierLocalizer, self).__init__()
self.num_classes = num_classes
# create cnn model
model = getattr(models, model_name)(pretrained=True)
# remove fc layers and add a new fc layer
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 6) # classifier + localizer
self.model = model
def forward(self, x):
x = self.model(x) # extract features from CNN
scores = x[:, : self.num_classes] # class scores
coords = x[:, self.num_classes :] # coordinates
return scores, torch.sigmoid(coords) # sigmoid output is in the range of [0, 1]
network = ClassifierLocalizer(model_name='resnet18')
Loss function
As we discussed before, we have two different tasks in this example. These tasks need different loss functions; Cross-Entropy loss for the classification and Mean Square Error loss for the regression. Below, we define a new loss function class that sums both losses to considers them simultaneously. However, as the regression is relatively a simpler task here (due to similarity of coordinates in the images), we apply a lower weight to MSEloss.
class ClassificationRegressionLoss(nn.Module):
def __init__(self, W):
super(ClassificationRegressionLoss, self).__init__()
self.ce_loss = nn.CrossEntropyLoss() # size_average=False
self.mse_loss = nn.MSELoss()
self.W = W
def forward(self, y_pred, y_true):
loss_cls = self.ce_loss(y_pred[0], y_true[0][:, gender_index]) # Cross Entropy Error (for classification)
loss_reg1 = self.mse_loss(y_pred[1][:, 0], y_true[1][:, 0] / h) # Mean Squared Error for X_L
loss_reg2 = self.mse_loss(y_pred[1][:, 1], y_true[1][:, 1] / w) # Mean Squared Error for Y_L
loss_reg3 = self.mse_loss(y_pred[1][:, 2], y_true[1][:, 2] / h) # Mean Squared Error for X_R
loss_reg4 = self.mse_loss(y_pred[1][:, 3], y_true[1][:, 3] / w) # Mean Squared Error for Y_R
total_loss = loss_cls + self.W * (loss_reg1 + loss_reg2 + loss_reg3 + loss_reg4)
return total_loss
Training
optimizer = optim.SGD(network.parameters(), lr=learning_rate, weight_decay=0.001)
loss_function = ClassificationRegressionLoss(W)
exp = Experiment(
"./saves/two_task_example",
network,
optimizer=optimizer,
loss_function=loss_function,
device=device,
)
exp.train(train_dataloader, valid_dataloader, epochs=num_epochs)
Evaluation
As you have also noticed from the training logs, in this try we achieved the best performance (considering the validation loss) at the 15th epoch. The weights of the network for the corresponding epoch have been automatically saved by the Experiment function and we use these parameters to evaluate our algorithm visually. For this purpose, we utilize the load_checkpoint method and set its argument to best to load the best weights of the model automatically. Finally, we take advantage of the evaluate function of Poutyne, and apply it to the validation dataset. It provides us the predictions as well as the ground-truth for comparison, in case of need.
exp.load_checkpoint("best")
model = exp.model
loss, predictions, ground_truth = model.evaluate_generator(test_dataloader, return_pred=True, return_ground_truth=True)
The callbacks feature of Poutyne, also used by the Experiment class, records the training logs. We can use this information to monitor and analyze the training process.
logs = pd.read_csv("./saves/two_task_example/log.tsv", sep="\t")
print(logs)
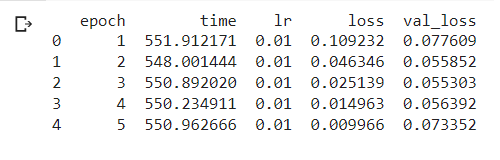
train_loss = logs.loss
valid_loss = logs.val_loss
plt.plot(train_loss)
plt.plot(valid_loss)
plt.legend(["train_loss", "valid_loss"])
plt.title("training and validation losses")
plt.show()
We can also evaluate the performance of the trained network (a network with the best weights) on any dataset, as below:
exp.test(test_dataloader)
Now let’s evaluate the performance of the network visually.
sample_number = 123
image = test_subset[sample_number][0]
image = image.permute(1, 2, 0).detach().numpy()
image_rgb = cv2.cvtColor(np.float32(image), cv2.COLOR_BGR2RGB)
image_rgb = image_rgb * imagenet_std + imagenet_mean
gender = "male" if np.argmax(predictions[0][sample_number]) == 1 else "female"
print("Gender is:", gender)
(x_L, y_L) = predictions[1][sample_number][0:2] * image_size
(x_R, y_R) = predictions[1][sample_number][2:4] * image_size
x_L, x_R = int(x_L), int(x_R)
y_L, y_R = int(y_L), int(y_R)
image_rgb = cv2.drawMarker(image_rgb, (x_L, y_L), (0, 255, 0))
image_rgb = cv2.drawMarker(image_rgb, (x_R, y_R), (0, 255, 0))
image_rgb = cv2.cvtColor(np.float32(image_rgb), cv2.COLOR_BGR2RGB)
image_rgb = np.clip(image_rgb, 0, 1)
plt.imshow(image_rgb)
plt.axis("off")
plt.show()
